
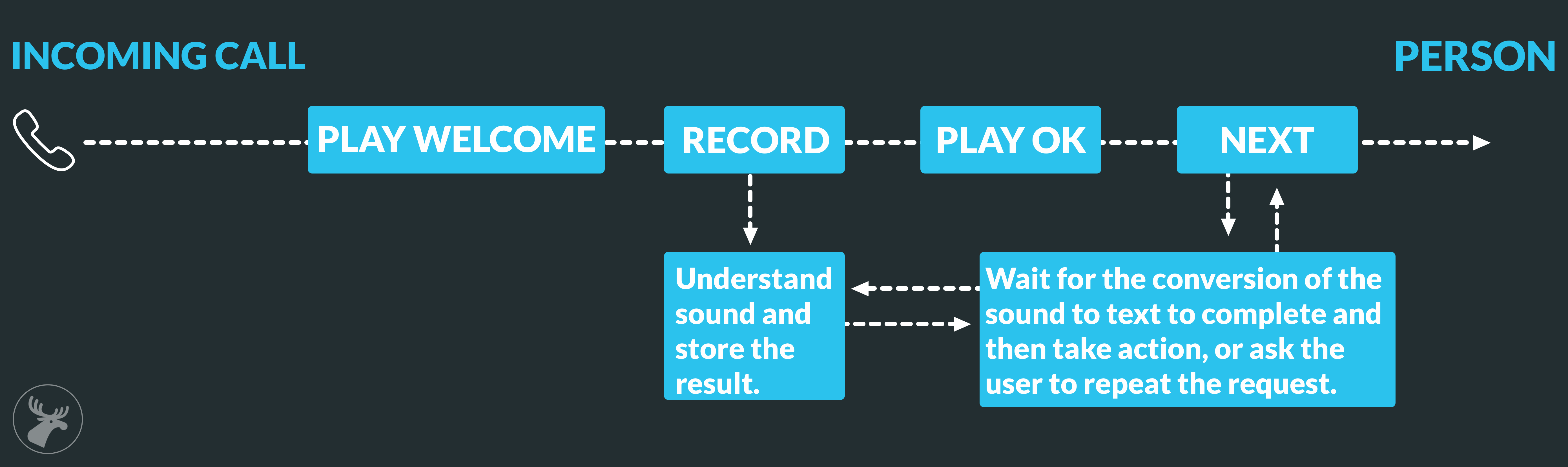
Call flow
Here is an overview of how the systems are connected.
- Call arrives from someone.
- A welcome-sound file is played to the caller.
- A recording is then started.
- When 3 seconds of silence is detected, or when a digit is pressed on the phone, the recording stops.
- Once the recording is complete, a request is sent to the set endpoint informing it that the recording is now available for download. At this point it’s possible to start the transcription of the recording.
- In parallel with the transcription, it is possible to make actions in the call, e.g. playing a sound saying - “wait a second”.
- The next step is to check the text content and take an appropriate action.
- In this example I connect the call to the correct number depending on the name in the recording.
Endpoints
To handle this I created two endpoints.
/recording
This is the endpoint that will be informed when new sound files are available for a download in the 46elks API in order to send it to the speech recognition API.
/whatnow
This is the endpoint that will be informed when the caller is ready to be forwarded to the telephone requested. This endpoint needs to wait for the recording to be transcribed.
Soundfiles:
I created 4 sound files:
- welcome.wav : "Welcome how can i help you?"
- ok_wait.wav : "Ok I’ll see what I can do."
- nosound.wav : "Sorry I did not hear what you said, can you please repeat?"
- busy.wav : "The telephone was busy, what do you want me to do?"
Parts on of the process
First step is to add a start JSON to voice_start on the number for the incoming call.
Initial voice start
The call starts with the welcome.wav, after that the sound is recorded and then ok_wait.wav is played and lastly the request to the /whatnow endpoint is made.
voice_start on number:
{
"play": "https://yourserver.com/sounds/welcome.wav",
"next": {
"record": "https://yourserver.com/api/recording",
"next": {
"play": "https://yourserver.com/sounds/ok_wait.wav",
"next": "https://yourserver.com/api/whatnow"
}
}
}
Handle recording
The recording the handled by downloading the sound file and then converting it into a BASE64 string as required by the voice recognition API.
First part of recording endpoint
// Set auth header.
$opts = array(
'http' => array(
'method' => 'GET',
'header' => "Authorization: Basic ".
base64_encode('<apiusernam>:<apipassword>')."\r\n",
'timeout' => 180
)
);
$context = stream_context_create($opts);
// Download sound file content.
$sound = file_get_contents($_POST['wav'], false, $context);
$sound = base64_encode($sound);
Ask Speech API for text
When the BASE64 string is available the request to the Google Speech API is made. The reason for using the Google Speech API in this example is that is supports the format of the sound files as is received from the 46elks API. And also Swedish along with lots of other languages is supported.
Second part of recording endpoint
$apirequest = array(
"config"=> array(
"encoding"=> "LINEAR16",
"sampleRate"=> 8000,
"languageCode"=> "sv-SE",
"speechContext" => array (
"phrases" => array("call","martin","johannes")
),
"audio" => array(
"content"=>$sound
)
);
$data_string = json_encode($apirequest);
$ch = curl_init('https://speech.googleapis.com/v1/speech:syncrecognize?key=<api-key>');
curl_setopt($ch, CURLOPT_CUSTOMREQUEST, "POST");
curl_setopt($ch, CURLOPT_POSTFIELDS, $data_string);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_HTTPHEADER, array(
'Content-Type: application/json',
'Content-Length: ' . strlen($data_string))
);
$text = curl_exec($ch);
Handle the text from the API
The API will then reply with different options of what the sound could mean as text. A simple solution is to select one with the highest accuracy. And then store that text in a local file, database, queue, etc.
Third part of recording endpoint
$texts = json_decode($text,true);
$accuracy = 0;
$besttext = '';
foreach($texts['results'][0]['alternatives'] as $alternative{
if($accuracy < $alternative['confidence']){
$besttext = $alternative['transcript'];
}
}
file_put_contents('calls/'.$_POST['callid'],$besttext);
Check that the recording is not mute
If the recording was completely quiet there will not be any recording data, in this case it would be useful to ask the user the repeat the request.
First part of /whatnow endpoint
$opts = array(
'http' => array(
'method' => 'GET',
'header' => "Authorization: Basic ".
base64_encode('<api-username>:<api-password>'). "\r\n",
'timeout' => 180
)
);
$context = stream_context_create($opts);
// Get call information:
$calldata = file_get_contents(https://api.46elks.com/a1/calls/$_POST['callid'], false, $context);
$calldata = json_decode($calldata);
$latestrecordresult = "";
foreach($calldata['actions'] as $action){
if(isset($action['actions'])){
$latestrecordresult = $action['result'];
}
}
if($latestrecordresult ==! "ok"){
print <<<END
{
"play": "https://yourserver.com/sounds/nosound.wav",
"next": {
"record": "https://yourserver.com/api/recording",
"next": {
"play": "https://yourserver.com/sounds/ok_wait.wav",
"next": "https://yourserver.com/api/whatnow"
}
}
}
END;
die();
}
Wait for recording to be transcribed then handle text.
The transcription may not be fast enough, so some time might be needed for the file to be created. And then take action. In this example I waited for 13 seconds before concluding that the transaction failed.
Second part of /whatnow endpoint
for($i = 0; $i < 13; $i++){
sleep(1);
if(file_exists('calls/'.$_POST['callid'])){
$text = file_get_contents('calls/'.$_POST['callid']);
$to = False;
if(stristr($text,'martin')){
$to="+4672317500";
}
elseif (stristr($text,'johannes')){
$to="+46766861004";
}
if($to){
print <<<END
{
"connect": "{$to}",
"busy": {
"play": "https://yourserver.com/sounds/busy.wav",
"next": {
"record": "https://yourserver.com/api/recording",
"next": {
"play": "https://yourserver.com/sounds/ok_wait.wav",
"next": "https://yourserver.com/api/whatnow"
}
}
}
}
END;
die();
}
}
}
If all fails say sorry try again.
And if all else fails ask the user for input again. Simply play the sound file to the user and make a new recording request.
Third part of /whatnow endpoint
print <<<END
{
"play": "https://yourserver.com/sounds/sorry.wav",
"next": {
"record": "https://yourserver.com/api/recording",
"next": {
"play": "https://yourserver.com/sounds/ok_wait.wav",
"next": "https://yourserver.com/api/whatnow"
}
}
}
END;




